Speech-to-text name accuracy - why spelling still fails

Picking up where we left off
In the first article, we showed why getting names and emails right is such a basic, yet critical, challenge for voice AI. A missed letter, a dropped "at", and suddenly the whole flow collapses: no email gets sent, no follow-up call happens, no ticket can be found.
That piece was about the why. Why it matters. Why this tiny detail can make or break trust in a voice system.
In this second article, we move from the why to the what. What happens if we take real-world Flemish names and emails and run them through today's best-known speech-to-text (STT) engines? We'll look at spoken names, spelled names, and email addresses. The goal isn't to bash these tools – they're powerful – but to show their limits when the data isn't free-flowing conversation but structured contact details.
Speech-to-Text (STT) results
To set a baseline, I ran 100 Flemish recordings – 50 spoken by a male voice, 50 spoken by a female voice. Each contained first names, last names, spelled versions, and email addresses. These went through five engines: Whisper (Base, Medium, Large), Deepgram Nova (2 & 3), and Scribe v1.
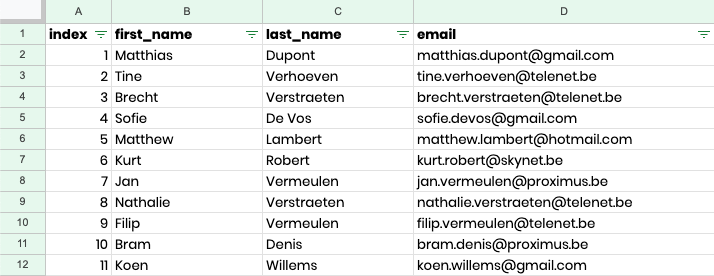
The results

Key patterns
- Spoken names are mostly fine. Bigger models handle Flemish names better, but errors remain.
- French names are easier than Dutch ones (Laurent, Dubois ↔ Stijn, Verstraeten).
- Spelled names almost never work. Engines turn letter-by-letter input into broken words.
- Emails looked partly right but were never usable. The spelled name portion inside the email was often correct, but the syntax was always wrong: none of the engines produced the @ symbol, so even high scores don't mean valid email addresses.
Why it happens
STT models are built for flowing conversation, not structured data. They try to make words from sounds. That's why "@" becomes "at", and why spelled names turn into nonsense.
But in practice, companies don't use raw STT engines directly. They use voice agent platforms that wrap around them. So we tested those too.
Voice agent test
Next, I tried the same thing with a simple voice agent, built using VAPI and ElevenLabs Conversational Agent. These platforms don't just transcribe – they add prompts, logic, and tool calls on top of the raw STT.
The agent asks for a name and email, and then calls two simple tools to store what it thinks it heard before confirming with the user.
The two tool calls
store_full_name– triggered as soon as the agent extracts a first and last name. It saves both, plus the raw snippet of what was heard. Even if the name is wrong, the tool call is made immediately.store_email_address– triggered as soon as an email is detected. Again, the call happens straight away, with the raw transcription passed along.
This design makes the flow more realistic: the system stores data instantly, then circles back to check if it was right. It also shows why small errors matter – the wrong name or email often gets saved first, and corrections don't always flow through.
Spelling takes time
User: It's Nathalie Verstraeten
Transcribed: "Natalie Verstraten"
Agent: Is that N-A-T-A-L-I-E, last name V-E-R-S-T-R-A-T-E-N?
User: No, N-A-T-H-A-L-I-E, V-E-R-S-T-R-A-E-T-E-N.
Agent: Got it. Nathalie Verstraeten.
User: My email is nathalie.verstraeten@hotmail.com
Transcribed: "My email is natalie.verstraten.hotmail.com"
User: No! 🤯
...
It eventually gets there, but it's cumbersome and takes a lot of corrections and spelling.
Spelling still broken
Even with careful spelling, errors creep in. NATO alphabet could help, but nobody in Belgium uses it naturally. So we're stuck between slow spelling and incorrect capture.
Corrections don't carry over
User: nathalie.verstraeten@hotmail.com
Stored: natalie.verstraten@telenet.be ❌
Even after the correction, the email is wrong. Fixing the name once doesn't fix it everywhere.
Takeaways
- Spelling is slow. Even simple names like Nathalie Verstraeten took multiple back-and-forth turns to get right.
- Spelling is unreliable. Letter-by-letter input is almost always garbled, and the NATO alphabet isn't practical in Belgium.
- Corrections don't propagate. Fixing a name once doesn't automatically fix it inside the email field.
- Emails look accurate but aren't valid. Engines often capture the spelled name portion correctly, but the overall syntax is broken – the @ symbol never appears, so the result isn't a usable address.
These experiments show there isn't one single problem – there are several. And each will need its own way forward. In Part 3 of this series, we'll look at the different strategies that can actually make this work in practice.
BLOG


.png)
